DAEDALUS System Architecture
Mechanism Design via Adversarial RL — The first environment that trains an LLM to be a referee, designing rules that constrain self-interested agents toward socially optimal outcomes.
The Core Inversion
Every RL agent ever trained — from AlphaGo to trading bots — is a player. DAEDALUS trains the referee — the entity that sets rules so self-interested agents produce good outcomes despite themselves.
Traditional RL
Train the Player
Optimize within fixed rules
DAEDALUS
Train the Referee
Design rules that produce desired equilibria
Three-Layer Environment
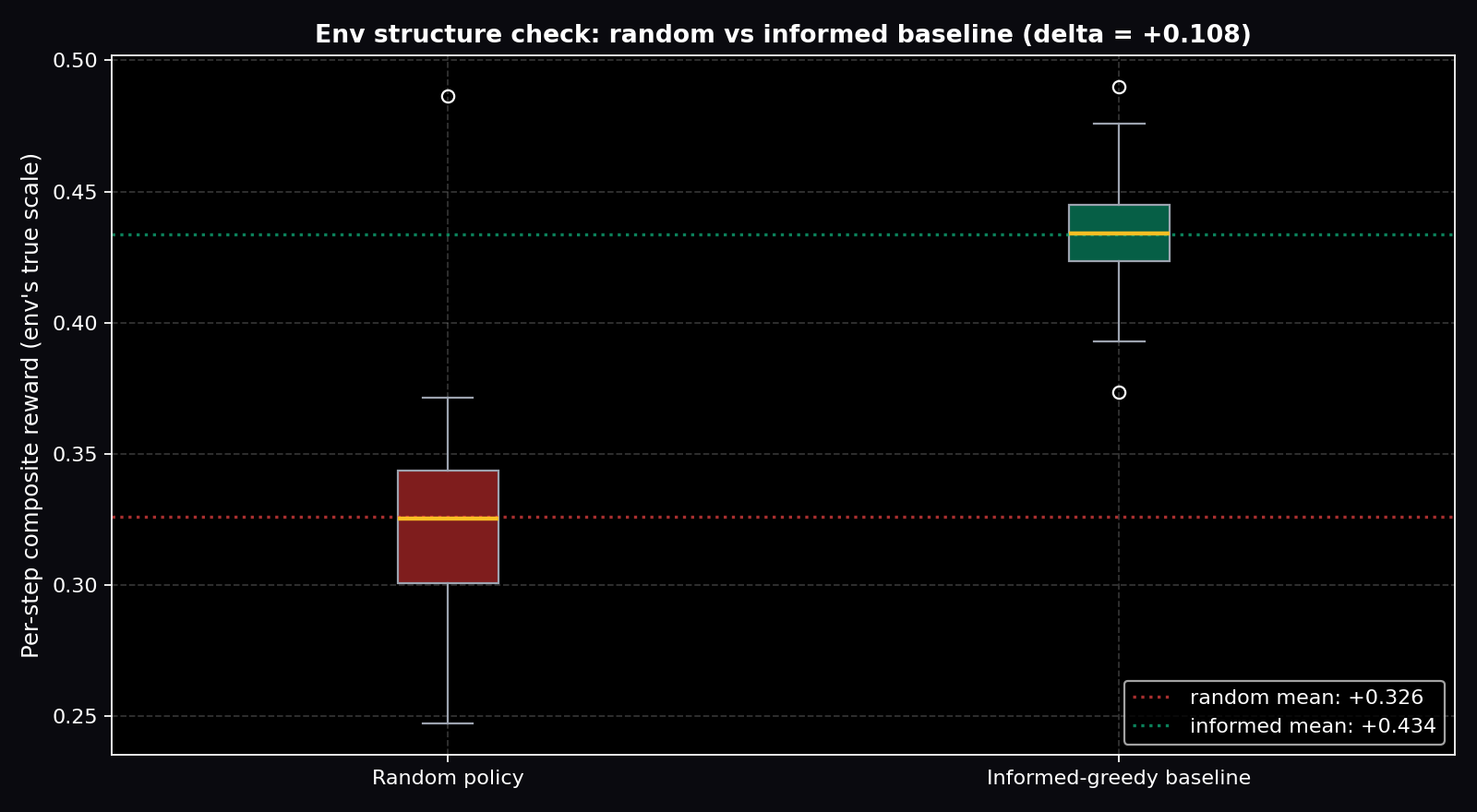
The designer operates under partial observability — seeing only aggregate market outcomes, never individual utility functions.
Adversarial Agent Taxonomy
🎯 Truthful Bidder
Bids true valuation. Baseline welfare measurement. Naive participants.
📉 Bid Shader
Shades bid below valuation. Adapts based on clearing prices. BNE: v×(n-1)/n.
🤝 Colluder
Coordinates with partner. Rotates wins. Exploits transparency for cartel enforcement.
🚪 Strategic Dropout
Exits if surplus < outside option. Forces individual rationality constraints.
💣 Budget Exploiter
Fixed budget. Tests payment rule edge cases. Drains market liquidity.
Multiplicative Reward Function
All objectives must be jointly positive — you cannot sacrifice one to maximize another.
Exploitation Dynamics
Five simultaneous attack vectors the designer must defend against:
1. Bid Shading — In first-price auctions, BNE bid = v×(n-1)/n. Defense: Switch to second-price or calibrate reserves.
2. Collusion — Cartel suppresses competition by rotating wins. Revenue loss ∝ k/n. Defense: Hide winner identity, randomize reserves.
3. Strategic Dropout — Raising reserves triggers exit cascade. Defense: Calibrate near outside option value.
4. False Stability — Mechanism appears stable while coalition forms. Defense: 20-round temporal window, trend features.
5. Transparency Paradox — Revealing info reduces shading but enables collusion. Defense: Targeted opacity (reveal prices, hide winners).
State & Action Spaces
Observable State: mechanism config (18 floats), market outcomes (7 metrics × 20 rounds), population proxies (9 stats), curriculum stage.
Action Space: Structured JSON — auction type (discrete), info flags (5 binary), reserve price (continuous [-0.2, +0.2]), penalties (3 continuous [0,3]), coalition policy (discrete).
Hidden State: Private valuations, utility parameters, coalition membership, agent type, strategy parameters — never revealed.
OpenEnv Compliance
# OpenEnv API
env = DaedalusEnvironment()
obs = env.reset() # New market scenario
obs, reward, done, info = env.step(mechanism_config_json)
state = env.state() # Current observable state
# Themes: #1 Multi-Agent Interactions + #4 Self-Improvement (curriculum)
# Verifiable rewards: multiplicative composite from simulation
# Adversarial co-evolution: sub-agents adapt within episodes
Training Pipeline & Setup
Complete training setup using OpenEnv + TRL GRPO + Unsloth. Trained on 1×L4 (HF Jobs); checkpoint pushed to kabilesh-c/daedalus-designer-v2.
Live Training Evidence
Plots below are generated directly from the real training_history.json shipped in this Space (download: training_history.json, summary CSV: training_metrics.csv).
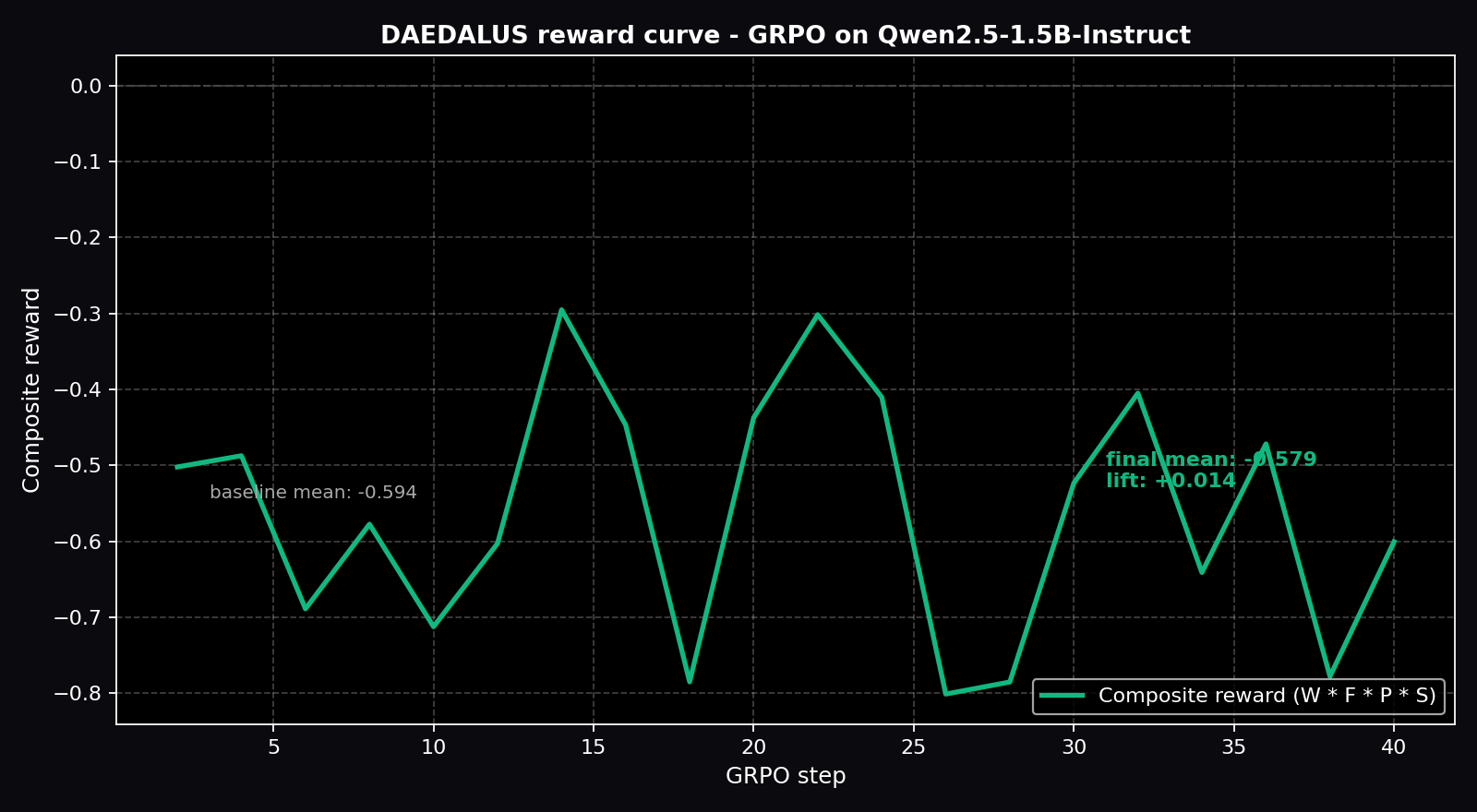
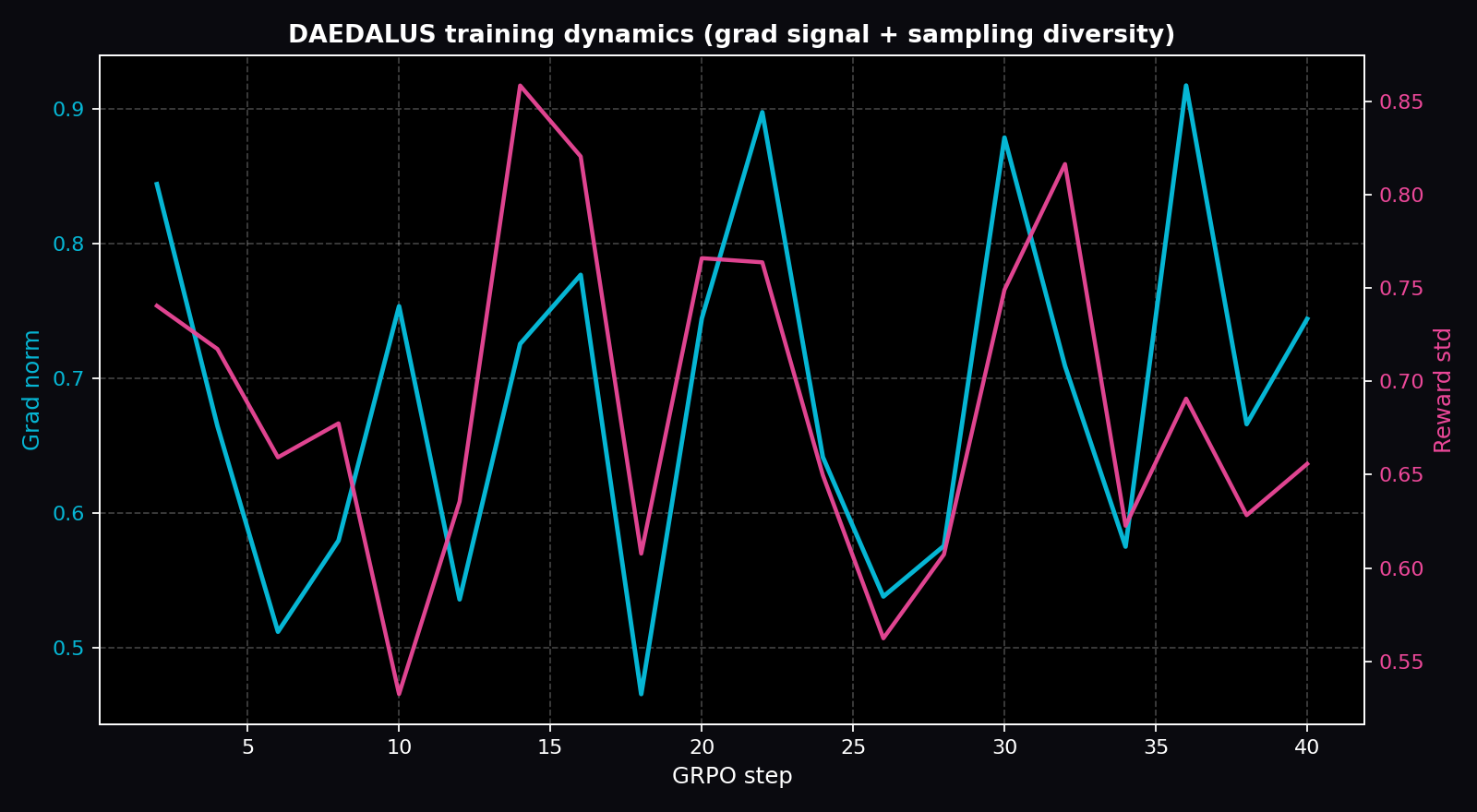
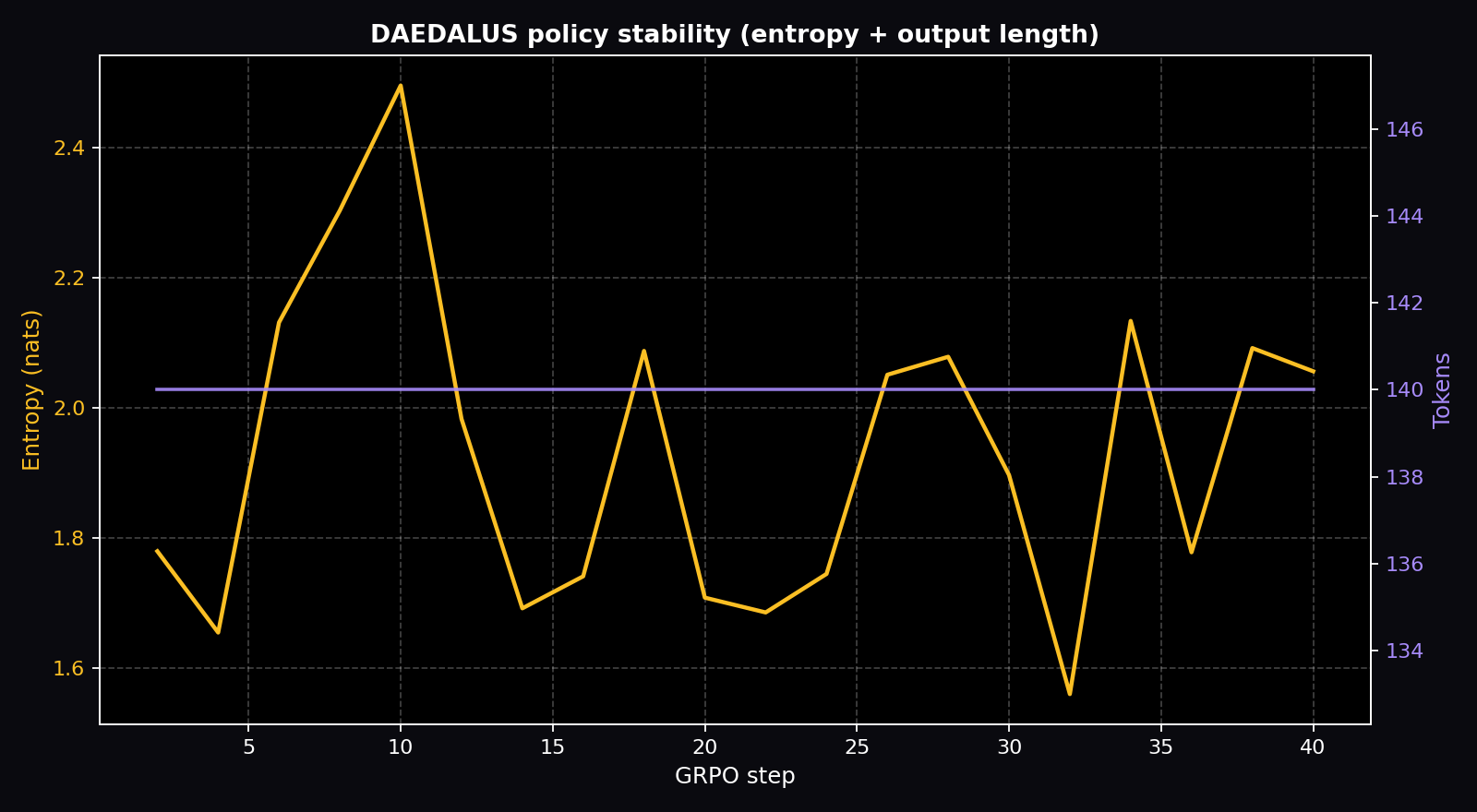
Per-step gradient values (first 10 of 20 logged)
Raw values straight from training_history.json. Hover the plots above for the full series.
| step | grad_norm | reward | reward_std | entropy | comp_len |
|---|
Model Architecture
🧠 LLM Backbone
Qwen2.5-7B / Llama-3.1-8B
Frozen + LoRA rank 16
4-bit quantized via Unsloth
💭 Chain-of-Thought
Economic reasoning trace
Welfare/fairness analysis
Exploitation detection
📋 Structured JSON
Valid mechanism config
Schema-constrained output
GRPO optimization
Curriculum Learning (5 Stages)
Pure Truthful Market
All agents bid truthfully. Learn baseline tradeoffs. R > 0.75 for 50 episodes.
+ Bid Shaders (30%)
Multi-item auctions. Info policy becomes critical. R > 0.65 for 100 episodes.
+ Dropout (20%)
Reserve price tension — raising reserves triggers exit. R > 0.60 for 100 episodes.
+ Colluders (20%)
Transparency enables cartel enforcement. R > 0.55 for 150 episodes.
Full Adversarial
All types, Dirichlet-sampled proportions. Budget exploiters added. Eval benchmark.
Colab Training Setup
# ═══ Step 1: Install Dependencies ═══
!pip install -q openenv trl unsloth transformers datasets accelerate
!pip install -q torch --index-url https://download.pytorch.org/whl/cu121
# ═══ Step 2: Load Model with Unsloth ═══
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
"unsloth/Qwen2.5-7B-Instruct",
max_seq_length=4096,
load_in_4bit=True,
dtype=None,
)
model = FastLanguageModel.get_peft_model(
model,
r=16, lora_alpha=16,
target_modules=["q_proj","k_proj","v_proj","o_proj",
"gate_proj","up_proj","down_proj"],
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
)
# ═══ Step 3: Define Reward Functions ═══
def welfare_reward(output, env_state):
"""Allocative efficiency: actual/theoretical max welfare"""
return env_state['welfare_ratio']
def fairness_reward(output, env_state):
"""1 - Gini coefficient of payment distribution"""
return 1.0 - env_state['gini_coefficient']
def participation_reward(output, env_state):
"""Fraction of agents actively bidding"""
return env_state['participation_rate']
def stability_reward(output, env_state):
"""Consistency of welfare over recent rounds"""
return env_state.get('stability_score', 0.8)
def composite_reward(output, env_state):
"""Multiplicative composite — all must be positive"""
w = welfare_reward(output, env_state)
f = fairness_reward(output, env_state)
p = participation_reward(output, env_state)
s = stability_reward(output, env_state)
return w * f * p * s
# ═══ Step 4: Environment Rollout ═══
from daedalus.env import DaedalusEnvironment
def rollout_fn(prompts, model, tokenizer):
env = DaedalusEnvironment()
rewards = []
for prompt in prompts:
obs = env.reset()
# Format observation as prompt
state_desc = format_state(obs)
# Generate mechanism config
output = generate(model, tokenizer, state_desc)
# Step environment
obs, reward, done, info = env.step(parse_json(output))
rewards.append(reward)
return rewards
# ═══ Step 5: GRPO Training ═══
from trl import GRPOConfig, GRPOTrainer
config = GRPOConfig(
output_dir="./daedalus-checkpoints",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
num_generations=8, # G=8 samples per state
max_completion_length=512,
learning_rate=5e-6,
logging_steps=10,
save_steps=500,
bf16=True,
)
trainer = GRPOTrainer(
model=model,
config=config,
tokenizer=tokenizer,
reward_funcs=[
welfare_reward,
fairness_reward,
participation_reward,
stability_reward,
composite_reward,
],
train_dataset=dataset,
)
trainer.train()
# ═══ Step 6: Save & Export ═══
model.save_pretrained_merged(
"daedalus-trained",
tokenizer,
save_method="merged_16bit"
)
GRPO Configuration
Why GRPO over PPO: No separate value head needed. For each state, sample G=8 mechanism configurations, evaluate each with market simulator, compute relative advantages within group. More stable for LLM policies.
Key Parameters: G=8 samples per state, gamma=0.99 discount, LoRA rank 16, learning rate 5e-6, 128 parallel rollouts per batch.
Reward anti-hacking: Sub-agent simulation runs 10 rounds per step; reward computed on rounds 6-10 (post-adaptation). Multiplicative structure prevents single-objective gaming.
OpenEnv Manifest
# openenv.yaml
name: daedalus
version: 1.0.0
description: Mechanism design training environment
agent:
type: llm_with_structured_head
observation_space:
type: dict
fields:
mechanism_config: float[18]
market_outcomes: float[7]
outcome_history: float[20, 7]
population_proxies: float[9]
environment:
n_agents: [8, 12]
episode_length: 50
rounds_per_step: 5
partial_observability: true
evaluation:
primary_metric: composite_reward
held_out_populations: 20
Deployment to HuggingFace Spaces
# Deploy environment server
pip install openenv
openenv init daedalus # Create scaffold
openenv push --space your-username/daedalus
# Or run locally
uvicorn server:app --host 0.0.0.0 --port 8000
# Docker
docker build -t daedalus .
docker run -p 8000:8000 daedalus
Product Paths
🏛️ Auction Design Advisory
Propose optimal mechanism configs and simulate against synthetic populations before deployment.
📈 Marketplace Optimization
Monitor live market health and suggest adjustments in response to exploitation patterns.
🔗 Tokenomics Simulator
Simulate token incentive mechanisms against MEV bots, whale coordination before deployment.